Manual picking of fractures and bedding planes from borehole image logs is one of the most time-consuming bottlenecks in reservoir characterization. GeoBFDT proposes a transformer-based alternative — end-to-end, mask-free, and trained on 14 wells in the Middle East — that predicts depth, dip, and azimuth in a single forward pass.
Abstract
Fractures and bedding planes govern fluid flow, mechanical stability, and well productivity. Identifying them from borehole image logs (BHIs) remains an expert-driven, laborious task — interpreters spend hours fitting sinusoids to resistivity images, well after well.
We introduce GeoBFDT (Geological Beddings and Fractures Detection Transformer), an end-to-end transformer architecture adapted from DETR that detects, localises, and parameterises geological features from two different microresistivity imaging tools (high-resolution borehole image logs) in a single pass. Trained on data from 14 wells, GeoBFDT directly predicts feature class, depth, dip, and azimuth without intermediate mask generation.
On the held-out test set, the model reaches F1-scores of ~65% for fractures and ~63% for beddings at a 3 cm depth threshold, rising to ~75% and ~69% respectively at 5 cm. Dip accuracy reaches ~90% at a 3° threshold for both classes; azimuth accuracy reaches ~92% (fractures) and ~84% (beddings) at a 15° threshold. The model also generalises with reduced — but useful — performance to horizontal wells.
Ablations show that, given the limited training set, a smaller ResNet-10 backbone outperforms deeper variants, and dynamic BHI logs outperform static ones. The result is a working pathway toward an automated, mask-free feature-picking workflow for BHI interpretation.
Background
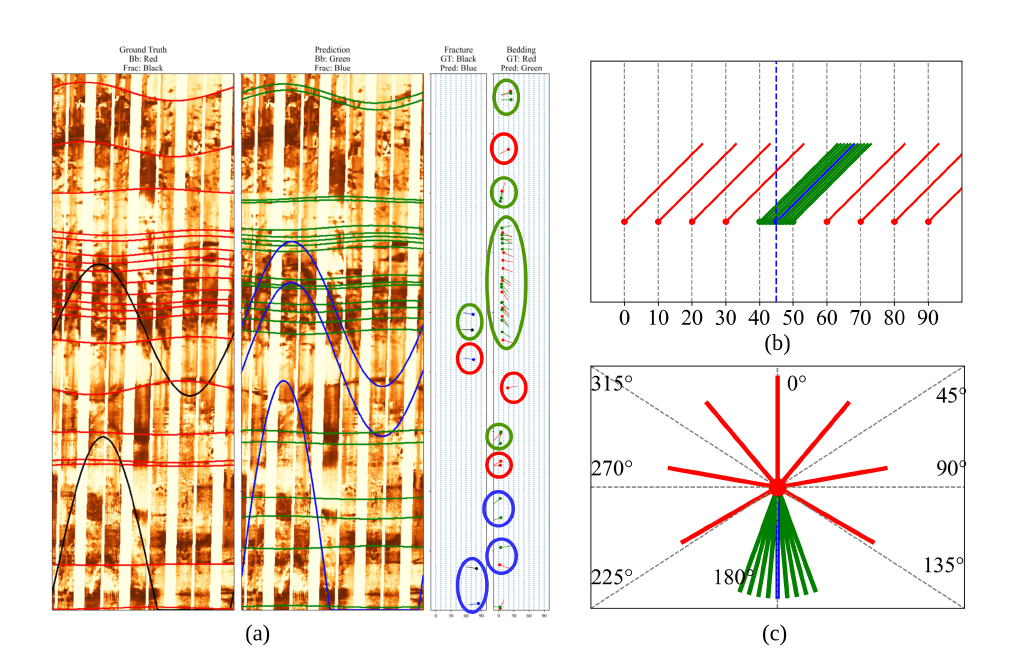
Borehole image logs are high-resolution resistivity images of the wellbore wall. When unrolled into a 2D image, planar geological features — bedding planes, fractures, faults — appear as sinusoids whose amplitude and phase encode dip and azimuth. Interpreting these sinusoids by hand is the standard workflow, and the standard bottleneck [1].
Earlier automation attempts followed two broad strategies. Classical signal-processing pipelines applied edge detection, Hough transforms, or template fitting to extract sinusoids, but degraded sharply in zones with intersecting features, conductive mud effects, or pad gaps [2]. A second wave used convolutional neural networks — typically Mask R-CNN or YOLO variants — to segment fracture pixels from background [3][4]. These models work, but inherit two structural limitations: they depend on pixel-accurate mask annotations (expensive to produce), and they decouple detection from geometric parameter estimation, requiring a second post-processing stage to fit sinusoids and extract dip and azimuth.
The detection transformer (DETR) framework reframed object detection as a direct set prediction problem [5]. A transformer encoder–decoder, paired with a bipartite-matching loss, predicts a fixed-size set of objects in one forward pass — no anchors, no non-maximum suppression, no masks. GeoBFDT adapts this idea to BHIs: each predicted 'object' is a geological feature, and the regression head emits depth, dip, and azimuth alongside the class label.
Method
Data. The training corpus comprises high-resolution borehole image logs from two different microresistivity imaging tools across 14 wells, spanning a mixture of vertical and deviated trajectories. Each log was decomposed into overlapping 800-pixel (~2.2 m) vertical patches to fit GPU memory while preserving sinusoid context. Both dynamic and static image normalisations were retained for ablation. Expert-picked sinusoids served as ground truth, with each annotation carrying a class label (fracture or bedding), a reference depth, a dip angle, and an azimuth.
Architecture. GeoBFDT follows the DETR template. A ResNet-10 backbone extracts a feature map from the input patch; this is flattened and fed into a transformer encoder, which models long-range dependencies along the depth axis. A transformer decoder attends to a fixed set of learned object queries, each of which is decoded into (a) a class logit and (b) a regression vector containing normalised depth, dip, and azimuth. The model emits N predictions per patch regardless of how many features are actually present.
GeoBFDT pipeline
BHI patch
Dynamic borehole image log, 800 px (~2.2 m) tall, overlapping windows.
ResNet-10 backbone
Shallow CNN extracts a feature map; chosen over deeper variants to avoid overfitting the 14-well corpus.
Transformer encoder
Self-attention models long-range structure along the depth axis.
Decoder + object queries
Fixed set of learned queries; each emits one candidate feature.
Class + (depth, dip, azimuth)
End-to-end regression — no mask, no post-hoc sinusoid fitting.
Bipartite matching loss
Hungarian matcher aligns predictions to ground truth one-to-one.
Bipartite matching loss. During training, predictions are matched one-to-one to ground-truth features using the Hungarian algorithm, with matching cost combining classification probability and a geometric distance over (depth, dip, azimuth). Unmatched predictions are pushed toward a 'no object' class. This removes the need for hand-tuned anchors and lets the network output a clean, deduplicated set.
Augmentation. Colour jitter, Gaussian noise, and vertical shifts were applied during training. Augmentation was not cosmetic — without it, the classification head collapsed to a near-100% class-error regime; with it, class error stabilised in the low single digits. Quality-control plots of per-well pixel-value distributions surfaced tool-malfunction artefacts (logs clipped to a 0–15 range instead of 0–255) before they corrupted training.
Results
Performance was evaluated at multiple depth, dip, and azimuth tolerances. The pattern is consistent: GeoBFDT picks fractures slightly more reliably than beddings, and dip/azimuth accuracy is high once a modest tolerance is allowed — exactly the regime that matters for downstream structural interpretation.
At a 3 cm depth threshold the model achieves F1 ≈ 65% (fractures) and ≈ 63% (beddings). Loosening to 5 cm — still well within interpreter agreement on real logs — raises both to ≈ 75% and ≈ 69%. Geometric parameters are stronger: dip accuracy reaches ≈ 90% for both classes at a 3° tolerance, and azimuth accuracy reaches ≈ 92% (fractures) / ≈ 84% (beddings) at a 15° tolerance.
Detection F1 at depth thresholds
Fractures F1 @ 3 cm
Beddings F1 @ 3 cm
Fractures F1 @ 5 cm
Beddings F1 @ 5 cm
Generalisation to horizontal wells, which were excluded from the main training distribution, was tested on five deviated wells. Fracture detection held at ≈ 55% at a 4 cm threshold — degraded relative to vertical wells, as expected, but enough to bootstrap interpretation in a regime where manual picking is hardest.
Geometric accuracy
Dip accuracy @ 3° (both classes)
Fracture azimuth @ 15°
Bedding azimuth @ 15°
Fracture F1 @ 4 cm, horizontal wells
Three ablations are worth flagging. First, larger backbones (ResNet-50, ResNet-101) underperformed ResNet-10 on this dataset size — a classic small-data overfitting signature. Second, dynamic logs consistently beat static logs as input, reinforcing the standard interpreter preference. Third, performance scales with the number of training wells, suggesting that the current 14-well ceiling is the binding constraint, not the architecture.
Small backbone, small data
Discussion
GeoBFDT's contribution is structural more than numerical. Existing CNN-based detectors hit comparable F1 on fracture pixels, but require mask supervision and a separate sinusoid-fitting step to recover dip and azimuth. By treating each feature as a typed object with a regression vector, GeoBFDT collapses detection and parameterisation into a single set-prediction problem — which is the natural shape of the interpreter's task.
The practical implication for asset teams is workflow time, not benchmark vanity. A model that produces a clean, deduplicated list of (class, depth, dip, azimuth) tuples per patch can be wired directly into existing tadpole-plot and structural-dip review tools. The interpreter's role shifts from picking to reviewing — accepting, rejecting, or nudging predictions — which is where geological judgement actually adds value.
Limitations are honest. Fourteen wells is a small corpus for a transformer, and the model has only been validated within one geological province. The 5 cm threshold at which F1 becomes useful is reasonable for most reservoir-scale work but uncomfortable for thin-bed analysis. Horizontal-well generalisation is partial. And the binary class taxonomy — fracture vs. bedding — does not yet distinguish conductive from resistive fractures, or open from healed, both of which matter for permeability prediction.
The natural next steps follow from the ablations. Expand the well count and the geological diversity. Sub-classify fractures by resistivity and aperture. Build an interactive review surface so corrections feed back into training. The architecture is not the bottleneck; the annotated data is.
By the numbers
GeoBFDT's headline results, condensed.
By the numbers
Wells in training corpus (two microresistivity imaging tools)
Fracture F1 at 5 cm depth threshold
Dip accuracy at 3° tolerance, both classes
Fracture azimuth accuracy at 15°
Fracture F1 on horizontal wells at 4 cm
References
[1] Automated Detection of Geological Features: Leveraging Deep Learning for Beddings and Fractures Identification in Image Logs. SPE Journal, 30(04): 1569–1587, SPE-223976-PA (2025). https://doi.org/10.2118/223976-PA
[2] Prior signal-processing approaches to sinusoid extraction from BHIs — Hough transforms, template fitting, edge-based detectors — reviewed in the foundational study [1] and references therein.
[3] He, K., Gkioxari, G., Dollár, P., & Girshick, R. Mask R-CNN. Proceedings of the IEEE International Conference on Computer Vision (2017). https://arxiv.org/abs/1703.06870
[4] Redmon, J., & Farhadi, A. YOLOv3: An Incremental Improvement (2018). https://arxiv.org/abs/1804.02767
[5] Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. End-to-End Object Detection with Transformers (DETR). ECCV (2020). https://arxiv.org/abs/2005.12872