“The next 10x in real-world model performance comes from improving the data, not the architecture. Production AI teams that haven't internalised this still ship the wrong things.
”
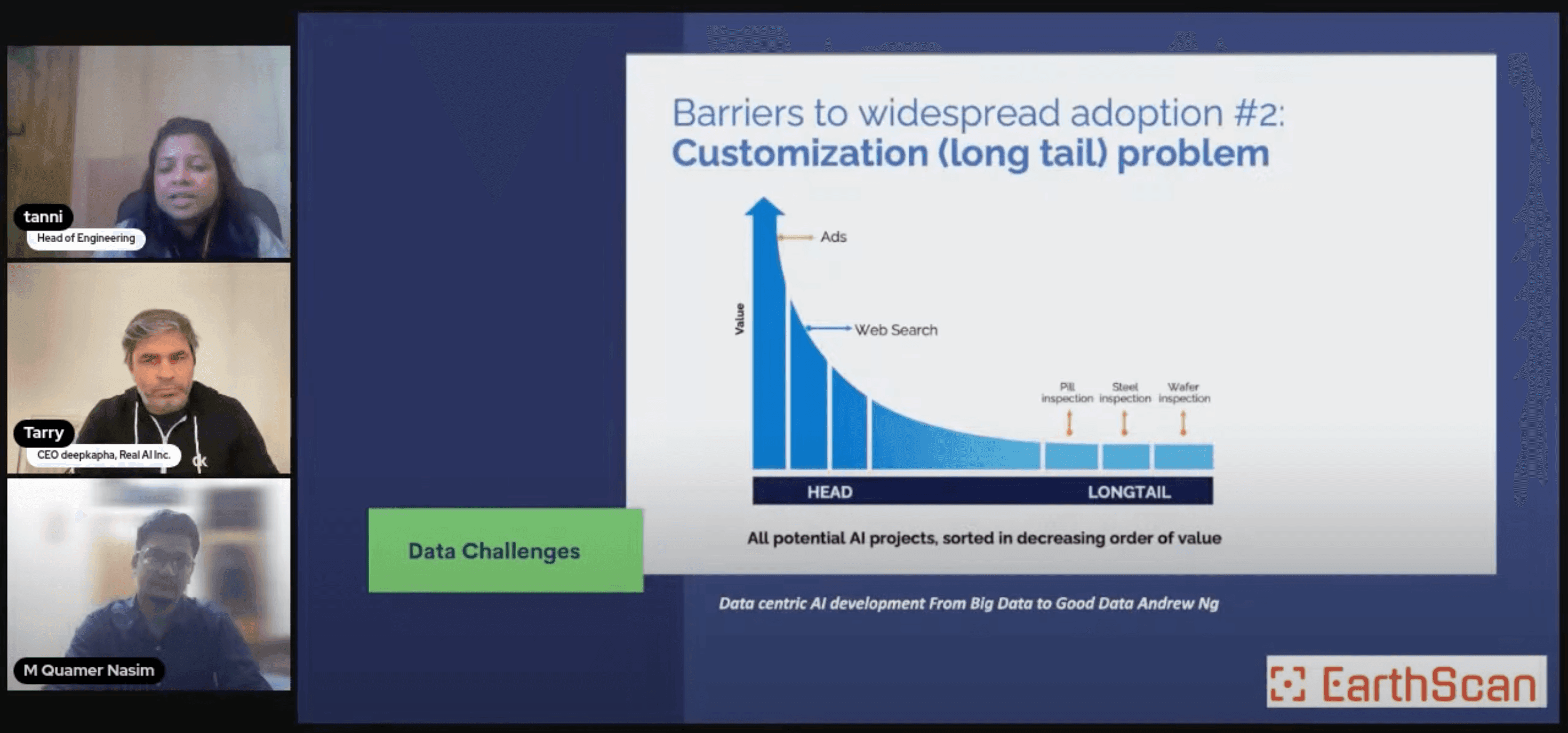
Andrew Ng's framing of data-centric AIAndrew Ng's framing — invest in better data, not bigger models. The next 10× in real-world performance comes from labelling, sampling, and augmentation, not from architecture search. — that the next 10x in real-world model performance comes from improving the data, not the architecture — is the lens this webinar uses to walk through what production AI teams actually spend their time on. Spoiler: it's not designing new transformer variants.
The reframe is sharper than it sounds. The same engineering hour, spent two ways, pulls in opposite directions:
Data ingestion — the unsexy 60% of any AI project
Data ingestion is the act of moving data from many sources (CRM, ERP, sensor streams, scraped logs, partner APIs) into a centralised lake or warehouse where it can be queried at scale. It's also where AI projects most often die — not from a lack of intelligence, but from a lack of plumbing.
The hard parts — open each for where it bites:
A source system silently changes a column type and you find out when a downstream join breaks — two months later, in production. The single most under-reported failure mode in production data pipelines; the fix is a schema contract validated on ingest, not a heroic debugging session in Q3.
Batch is cheap and easy; streaming is expensive and complicated. Most production systems need both — a batch backbone for the bulk and a streaming path for the freshness-critical slice — and the architecture cost is in drawing that line correctly, not in either pipe alone.
Knowing which row came from which source on which day is non-negotiable for regulated industries — energy included. Without row-level lineage you cannot answer an auditor, reproduce a model, or quarantine a bad source without re-ingesting everything.
A robust ingestion layer pays back compounding interest: every downstream model gets cleaner data, faster, and with audit trails the regulators can read.
The data pipeline — turning raw bytes into model-ready features
Past ingestion, the pipeline does the work nobody puts on a slide deck:
- Cleaning — null-handling, deduplication, type normalisation.
- Transformation — joins, aggregations, derived features.
- Validation — schema contracts, statistical tests on incoming distributions.
- Feature engineering — domain-specific transformations that turn raw fields into model inputs.
Investing in this layer once means every new model you ship onboards in days instead of weeks. Skipping it means every team rebuilds the same plumbing in slightly incompatible ways and the org accumulates technical debt that becomes impossible to refactor by year three.
MLOps — DevOps for the parts of the AI lifecycle that need it
- 1
Ingest
Curate + version the training data
- 2
Train
Reproducible runs, dataset + commit hashed
- 3
Deploy
APIs, A/B harnesses, batch scoring
- 4
Monitor
Drift detection + business-metric telemetry
- 5
Retrain
Triggered by drift, not by the calendar
MLOpsDevOps applied to the ML lifecycle — automated training, deployment, monitoring, retraining. The connective tissue that turns a notebook into a production system. is what you call DevOps once your artefacts include trained model weights, training datasets, and feature definitions in addition to source code. Its non-negotiable layers expand below:
Given a commit hash and a dataset hash, can you regenerate this model exactly? If not, you don't have MLOps yet — you have a notebook that happened to work once. Reproducibility is the floor everything else stands on.
Pushing models behind APIs, A/B harnesses, and batch scoring jobs — with the same rigour you'd apply to any production service: staged rollout, rollback, and a kill switch.
Drift detection, performance telemetry, and distribution-shift alerts — watching not just whether the model is up, but whether the world it was trained on still matches the world it's scoring.
Access control, audit logs, a model registry, and end-to-end lineage. The unglamorous layer that turns 'we think this model is compliant' into 'here is the record' — table stakes in energy, finance, and healthcare.
The non-negotiable rule: track business metrics alongside model metrics. If your fraud-detection model's AUC went up 2% but the actual loss rate stayed flat, your monitoring is wrong.
Data augmentation — making the model see more without collecting more
For computer vision and NLP, augmentation transforms training samples (rotation, scaling, cropping, colour-jittering, masking) to expand the effective training set without collecting new data. Done right, augmentation:
- Reduces overfitting on small datasets.
- Makes models robust to common real-world distortions.
- Costs nothing once the augmentation pipeline is in place.
Done wrong, it bakes in biased augmentations — e.g. randomly cropping medical images in a way that throws away the diagnostic region. Always validate augmented samples against the same QA bar you apply to original data.
AugMix — the underrated robustness method
AugMixRobust data-augmentation technique (Hendrycks et al., ICLR 2020). Mixes multiple augmentations consistently across a sample to improve out-of-distribution robustness without hurting in-distribution accuracy. (Hendrycks et al., ICLR 2020) is one of the most underrated augmentation methods we covered. Instead of picking one augmentation per training example, AugMix runs three moves:
Generate multiple augmentation chains
Several chains of varying severity are applied to the same image — not one transform, a family of them.
Mix their outputs
The chains' outputs are blended with random convex weights, so the model sees a continuum of corruptions, not discrete ones.
Enforce consistent predictions
The model is trained to predict the same thing across the original and the mixed versions — a Jensen-Shannon-divergence consistency loss ties them together.
The result: a model that's noticeably more robust to corruptions it never saw in training (the standard ImageNet-C benchmark), and produces better-calibrated uncertainty estimates.
For production deployments — where the inference distribution rarely matches the training distribution exactly — AugMix gives you a couple of extra points of robustness for almost no engineering cost.
Glossary
- AugMix
- Robust data-augmentation technique (Hendrycks et al., ICLR 2020). Mixes multiple augmentations consistently across a sample to improve out-of-distribution robustness without hurting in-distribution accuracy.
- Data-centric AI
- Andrew Ng's framing — invest in better data, not bigger models. The next 10× in real-world performance comes from labelling, sampling, and augmentation, not from architecture search.
- MLOps
- DevOps applied to the ML lifecycle — automated training, deployment, monitoring, retraining. The connective tissue that turns a notebook into a production system.
- Schema drift
- Silent change in source-data column types or shapes that breaks downstream joins. The single most under-reported failure mode in production data pipelines.
Closing thought
Data-centric AI is a re-framing, not a new technique. The components — robust ingestion, well-engineered pipelines, MLOps discipline, thoughtful augmentation — are old. What's new is the recognition that investing in these unglamorous layers delivers more business value than chasing the next 0.5% on a leaderboard.
For teams shipping AI in regulated industries — energy, finance, healthcare — this isn't optional. The model is the easy part.
Further reading
- Data augmentation guide — Machine Learning Mastery
- Data augmentation projects on GitHub
- AugMix paper (arXiv 1912.02781)